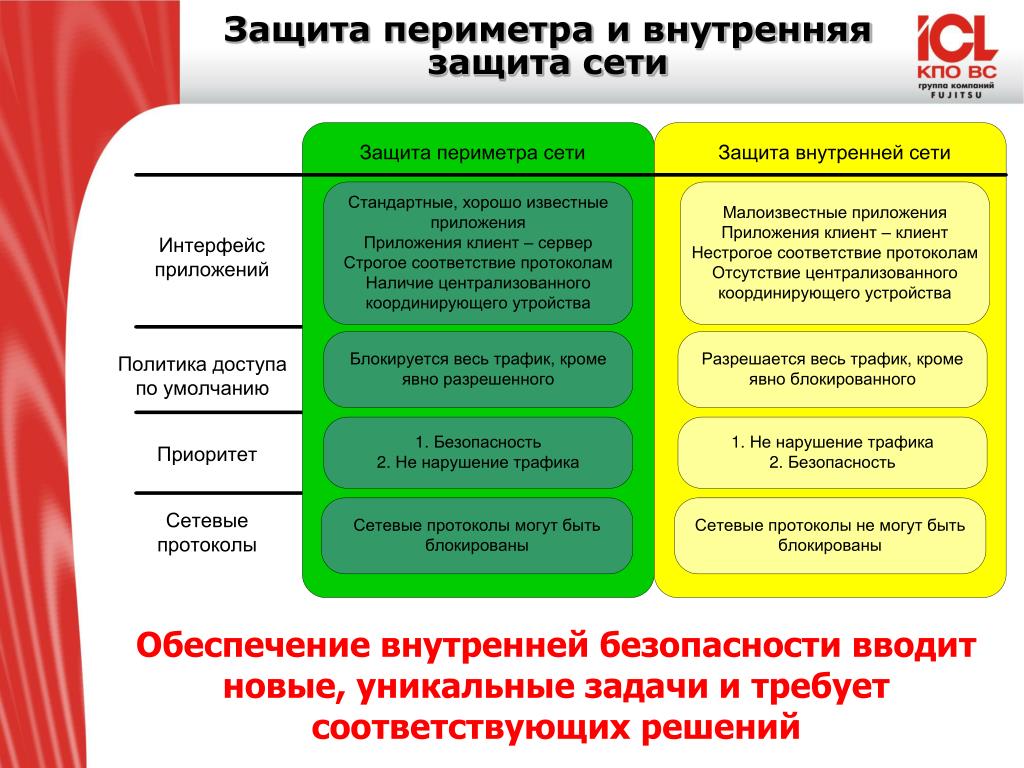
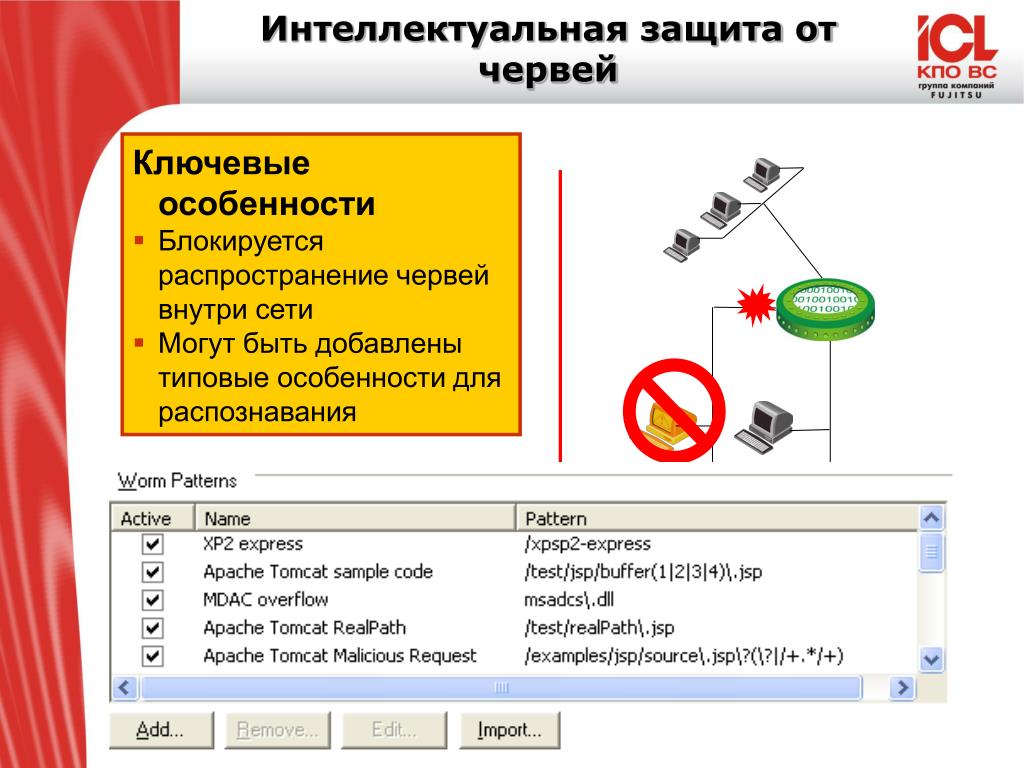
Содержание
Классификации по методу максимального подобия—Справка
Доступно с лицензией Spatial Analyst.
- Краткая информация
- Использование
- Синтаксис
- Пример кода
- Параметры среды
- Информация о лицензиях
Краткая информация
Выполняет классификацию по методу максимального подобия для набора каналов растра и создаёт классифицированный растр в качестве выходных данных.
Более подробно о том, как работает Классификация по методу максимального подобия
Использование
Любой файл сигнатур, созданный с помощью инструментов Создать сигнатуры, Редактировать сигнатуры или Изокластер, является действительным для использования в качестве входного файла сигнатур. Такой файл будет иметь расширение .gsg.
По умолчанию, на выходном растре будут классифицированы все ячейки, при этом к сигнатурам каждого из классов будут присоединены равные веса вероятностей.

Входной файл априорных вероятностей должен представлять собой ASCII-файл, состоящий из двух столбцов. Значения в левом столбце представляют идентификаторы классов (ID). Значения в правом столбце представляют априорные вероятности для соответствующих классов. Действительные значения априорных вероятностей для классов должны быть больше или равны нулю. Если в качестве вероятности задан ноль, класс не будет отображаться на выходном растре. Сумма заданных априорных вероятностей должна быть меньше или равна единице. Формат файла следующий:
1 .3 2 .1 4 .0 5 .15 7 .05 8 .2Классы, пропущенные в файле, получат среднюю априорную вероятность той части, которая останется от единицы. В примере выше, все классы с 1 по 8 представлены в файле сигнатур. Априорные вероятности классов 3 и 6 отсутствуют во входном файле априорной вероятности. Так как сумма всех вероятностей, определенных в файле выше, равна 0,8, остаток (0,2) делится на число не определенных классов (2).
Следовательно, классам 3 и 6 будет присвоена вероятность, равная 0,1, каждому.Заданная доля отклонения, которая лежит между двумя действительными значениями, будет присвоена следующему верхнему действительному значению. Например, значение 0,02 будет преобразовано в значение 0,025.
Существует прямая зависимость между числом неклассифицированных ячеек на выходном растре, вытекающем из доли отклонения, и числом ячеек, представленных суммой уровней доверия, меньших, чем соответствующее значение, введенное для доли отклонения.
Если входные данные представлены слоем, созданным на основании многоканального растра, содержащего более трёх каналов, операция будет выполняться для всех каналов, связанных с исходным набором данных, а не только для трёх каналов, которые загружены слоем (то есть, отображаются символами).
Существует несколько способов для указания поднабора каналов многоканального растра, которые нужно использовать в качестве входных данных инструмента.
- При использовании диалогового окна инструмента выберите многоканальный растр с помощью кнопки обзора , расположенной рядом с пунктом Каналы входного растра, откройте растр и выберите нужные каналы.
- Если многоканальный растр является слоем в Таблице содержания, можно использовать инструмент Создать растровый слой, чтобы создать новый многоканальный слой, содержащий только нужные каналы.
- Можно также создать новый набор данных, содержащий только нужные каналы, используя для этого инструмент Объединить каналы, входными данными для которого будет являться полученный набор данных.
- В Python нужные каналы можно указать как список напрямую в параметре инструмента.
Если имя класса в файле подписи отличается от идентификатора класса, в таблицу атрибутов выходного растра будет добавлено дополнительное поле CLASSNAME. Для каждого класса в этом поле выходной таблицы будет содержаться имя класса, связанное с этим классом.
Например, если имена классов файла подписи имеют описательные строковые имена (например, хвойные деревья, вода и город), эти имена будут перенесены в поле CLASSNAME.Расширение входного файла априорных вероятностей – .txt.
См. раздел Параметры среды анализа и Spatial Analyst для получения дополнительной информации о среде геообработки данного инструмента.

 Следовательно, классам 3 и 6 будет присвоена вероятность, равная 0,1, каждому.
Следовательно, классам 3 и 6 будет присвоена вероятность, равная 0,1, каждому.
 Например, если имена классов файла подписи имеют описательные строковые имена (например, хвойные деревья, вода и город), эти имена будут перенесены в поле CLASSNAME.
Например, если имена классов файла подписи имеют описательные строковые имена (например, хвойные деревья, вода и город), эти имена будут перенесены в поле CLASSNAME.Синтаксис
MLClassify (in_raster_bands, in_signature_file, {reject_fraction}, {a_priori_probabilities}, {in_a_priori_file}, {out_confidence_raster})| Параметр | Объяснение | Тип данных |
in_raster_bands [in_raster_band,…] | Входные каналы растров. Если значения каналов являются целочисленными или числами с плавающей точкой, то файл сигнатур допускает лишь целочисленные значения классов. | Raster Layer |
in_signature_file | Входной файл сигнатур, сигнатуры классов которого используются алгоритмом классификации по методу максимального подобия. Требуется расширение .gsg. | File |
reject_fraction (Дополнительный) | Это значение определяет, будет ли класс ячейки определяться исходя из вероятности того, насколько правильно она будет отнесена к одному из классов. Ячейки, вероятность правильного отнесения которых к любому из классов ниже, чем доля отклонения, получат значение NoData в выходном классифицированном растре. Ячейки, вероятность правильного отнесения которых к любому из классов ниже, чем доля отклонения, получат значение NoData в выходном классифицированном растре. Значение по умолчанию равно 0.0, означающее, что классифицированы будут все ячейки. Допустимыми типами данных являются
| String |
a_priori_probabilities (Дополнительный) | Задает, как будут определяться априорные вероятности.
| String |
in_a_priori_file (Дополнительный) | Текстовой файл, содержащий априорные вероятности для входных классов сигнатур. Входные данные для файла априорных вероятностей требуются, только если используется параметр ФАЙЛ. Расширением файла априорных вероятностей может быть расширение .txt или .asc. | File |
out_confidence_raster (Дополнительный) | Выходной набор растровых данных доверия показывает 14 уровней достоверности классификации, при этом более низкие значения уровней указывают на более высокую степень достоверности. Он будет целочисленного типа. | Raster Dataset |

 Если ячейки, классифицированные на определенном уровне достоверности, отсутствуют, то такой уровень достоверности не будет представлен в выходном растре доверия.
Если ячейки, классифицированные на определенном уровне достоверности, отсутствуют, то такой уровень достоверности не будет представлен в выходном растре доверия.Возвращаемое значение
| Название | Объяснение | Тип данных |
| out_classified_raster | Выходной классифицированный растр. Он будет целочисленного типа. | Raster |
Пример кода
MaximimumLikelihoodClassification Пример 1 (окно Python)
В этом примере создается выходной классифицированный растр, содержащий 5 классов, полученных из входного файла сигнатур и многоканального растра.
import arcpy
from arcpy import env
from arcpy.sa import *
env.workspace = "C:/sapyexamples/data"
mlcOut = MLClassify("redlands", "c:/sapyexamples/data/wedit5.gsg", "0.0",
"EQUAL", "", "c:/sapyexamples/output/redmlcconf")
mlcOut. save("c:/sapyexamples/output/redmlc")
 save("c:/sapyexamples/output/redmlc")
save("c:/sapyexamples/output/redmlc")
MaximimumLikelihoodClassification. Пример 2 (автономный скрипт)
В этом примере создается выходной классифицированный растр, содержащий 5 классов, полученных из входного файла сигнатур и многоканального растра.
# Name: MLClassify_Ex_02.py
# Description: Performs a maximum likelihood classification on a set of
# raster bands.
# Requirements: Spatial Analyst Extension
# Import system modules
import arcpy
from arcpy import env
from arcpy.sa import *
# Set environment settings
env.workspace = "C:/sapyexamples/data"
# Set local variables
inRaster = "redlands"
sigFile = "c:/sapyexamples/data/wedit5.gsg"
probThreshold = "0.0"
aPrioriWeight = "EQUAL"
aPrioriFile = ""
outConfidence = "c:/sapyexamples/output/redconfmlc"
# Check out the ArcGIS Spatial Analyst extension license
arcpy.CheckOutExtension("Spatial")
# Execute
mlcOut = MLClassify(inRaster, sigFile, probThreshold, aPrioriWeight,
aPrioriFile, outConfidence)
# Save the output
mlcOut. save("c:/sapyexamples/output/redmlc02")
 save("c:/sapyexamples/output/redmlc02")
save("c:/sapyexamples/output/redmlc02")
Параметры среды
- Автоподтверждение
- Размер ячейки
- Сжатие
- Текущая рабочая область
- Экстент
- Географические преобразования
- Маска
- Выходное ключевое слово конфигурации
- Выходная система координат
- Временная рабочая область
- Растр привязки
- Размер листа
Информация о лицензиях
- ArcGIS Desktop Basic: Требует Spatial Analyst
- ArcGIS Desktop Standard: Требует Spatial Analyst
- ArcGIS Desktop Advanced: Требует Spatial Analyst
Связанные разделы
Как работает инструмент Классификация по методу максимального подобия—Справка
Доступно с лицензией Spatial Analyst.
- Пример
Алгоритм, используемый инструментом Классификация по методу максимального подобия, основывается на двух основных принципах:
- Значения ячеек в выборке для каждого класса в многомерном пространстве подчиняются закону нормального распределения
- Используется теория Байе (теорема принятия решений)
Этот инструмент, при отнесении каждой ячейки к одному из классов, представленных в файле сигнатур, учитывает как средние, так и ковариации сигнатур классов. При допущении, что выборка для класса подчиняется нормальному распределению, класс может быть охарактеризован вектором среднего и матрицей ковариации. После присвоения этих двух характеристик каждому значению ячейки из каждого класса, для определения принадлежности ячеек к тому или иному классу, вычисляется статистическое правдоподобие. Если задана опция по умолчанию EQUAL для Взвешенной априорной вероятности, каждая ячейка будет отнесена к тому классу, вероятность принадлежности ячейки к которому максимальна.
При допущении, что выборка для класса подчиняется нормальному распределению, класс может быть охарактеризован вектором среднего и матрицей ковариации. После присвоения этих двух характеристик каждому значению ячейки из каждого класса, для определения принадлежности ячеек к тому или иному классу, вычисляется статистическое правдоподобие. Если задана опция по умолчанию EQUAL для Взвешенной априорной вероятности, каждая ячейка будет отнесена к тому классу, вероятность принадлежности ячейки к которому максимальна.
Если вероятность встречаемости некоторых классов выше (или ниже) среднего, должна использоваться опция FILE, работающая с Входным файлом априорной вероятности. Веса классов с определенными вероятностями задаются в файле априорных вероятностей. В такой ситуации, файл априорных вероятностей помогает в определении местоположения ячеек, которые попадают в статистическое перекрытие двух классов. Такие ячейки будут отнесены к соответствующему классу с большей точностью, что, в итоге, приводит к лучшим результатам классификации. Такой подход к классификации с применением взвешивания носит название байсовского классификатора.
Такой подход к классификации с применением взвешивания носит название байсовского классификатора.
При выборе опции SAMPLE, априорные вероятности, присвоенные всем классам, представленным во входном файле сигнатур, будут пропорциональны числу ячеек, отнесенных к каждой сигнатуре. Следовательно, классы, в которые попадает меньшее число ячеек, чем среднее для выборки, получат веса ниже среднего, а те, в которых ячеек больше, получат большие веса. В результате, к соответствующим классам будет отнесено большее или меньшее количество ячеек.
Когда выполняется классификация по методу максимального подобия, дополнительно может быть также создан выходной растр достоверности. Этот растр показывает уровни достоверности классификации. Число уровней достоверности равно 14; это число напрямую связано с числом действительных значений доли отклонения. Первый уровень достоверности, код которого на растре достоверности – единица, состоит из ячеек, удаленных от любого вектора среднего, хранящегося в файле сигнатур, на самое короткое расстояние; следовательно, классификация этих ячеек выполнена с наибольшей определенностью. Ячейки, составляющие второй уровень достоверности (значение ячейки 2 на доверительном растре) будут классифицированы, только если исключенная область равна 0,99 или меньше. Наименьший уровень достоверности имеет значение 14 на растре достоверности, показывающим ячейки, которые скорее всего будут неправильно классифицированы. Ячейки этого уровня достоверности не будут классифицированы, когда доля отклонения равна 0.005 или больше. Если ячейки, классифицированные на определенном уровне достоверности, отсутствуют, то такой уровень достоверности не будет представлен в выходном растре доверия.
Ячейки, составляющие второй уровень достоверности (значение ячейки 2 на доверительном растре) будут классифицированы, только если исключенная область равна 0,99 или меньше. Наименьший уровень достоверности имеет значение 14 на растре достоверности, показывающим ячейки, которые скорее всего будут неправильно классифицированы. Ячейки этого уровня достоверности не будут классифицированы, когда доля отклонения равна 0.005 или больше. Если ячейки, классифицированные на определенном уровне достоверности, отсутствуют, то такой уровень достоверности не будет представлен в выходном растре доверия.
Пример
В примере ниже показано, как Классификации по методу максимального подобия используется для выполнения управляемой классификации многоканального растра на 5 классов по типу землепользования.
Исходный многоканальный растр для классификации — это необработанный четырехканальный снимок со спутника Landsat TM на территорию северной части г. Цинциннати, штат Огайо.
Пример изображения с Landsat TM с каналами 4, 3 и 2, который отображается в псевдо цветах.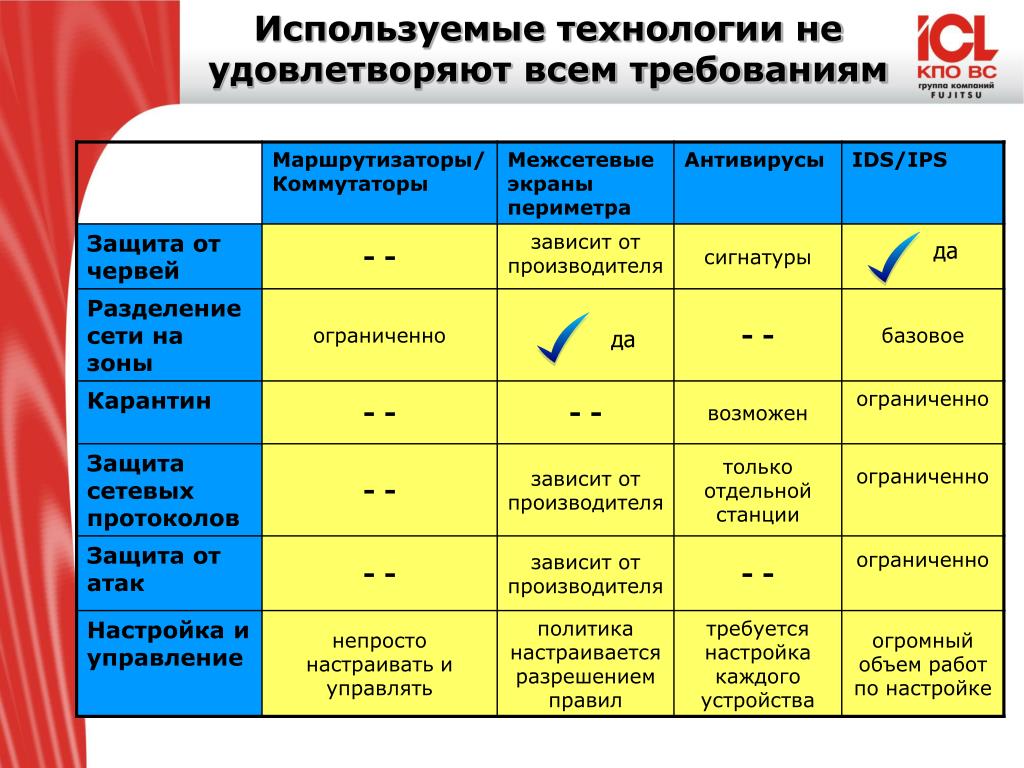
По изображению в классе объектов задаются пять классов землепользования для получения обучающих выборок: Коммерческое/Промышленное (Commercial/Industrial), Жилое (Residential), Пашни (Cropland), Леса (Forest) и Пастбища (Pasture). Инструмент Создать сигнатуры используется для вычисления статистики по классам для создания файла сигнатур.
С помощью входного многоканального растра и файла сигнатур, инструмент Классификация по методу максимального подобия используется для классификации ячеек растра на пять классов.
- Параметры, используемые в диалоговом окне инструмента Классификация по методу максимального подобия:
Входные каналы растра – northerncincy.tif
Входной файл сигнатур – signature.gsg
Выходной многоканальный растр – landuse
Исключенная область – 0.0
Взвешенная априорная вероятность – EQUAL
Входной файл априорной вероятности – <пусто>
Выходной растр достоверности – confidence_ras
Классифицированный растр выглядит следующим образом:
Выходная классифицированная карта землепользования.
Также будет создан выходной растр достоверности. Ниже приведена итоговая таблица атрибутов растра достоверности. В нем показано число ячеек, классифицированных с той или иной степенью доверия. Значение 1 имеет 0.995-процентную вероятность того, что ячейка классифицирована правильно. С этим уровнем доверия классифицировано 69 ячейки. Значение 5 имеет по крайней мере 0,9-процентную вероятность того, что ячейка классифицирована правильно, что меньше, чем 0.995. Имеется 744128 ячеек с вероятностью правильной классификации менее 0,005, им присвоено значение 14.
RECORD VALUE COUNT 0 1 69 1 2 462 2 3 1834 3 4 1123 4 5 2044 5 6 9140 6 7 28443 7 8 46781 8 9 63234 9 10 46393 10 11 42157 11 12 54506 12 13 37937 13 14 744128
Связанные разделы
Аутсорсинг процессов знаний (KPO) Определение
Что такое аутсорсинг процессов знаний (KPO)?
Аутсорсинг процессов знаний (KPO) — это аутсорсинг основных бизнес-операций, связанных с информацией. КПО предполагает найм на работу лиц, которые, как правило, имеют ученые степени и опыт в специализированной области.
КПО предполагает найм на работу лиц, которые, как правило, имеют ученые степени и опыт в специализированной области.
Информационная работа может выполняться работниками другой компании или филиала той же организации. Дочерняя компания может находиться в той же стране или в оффшорной зоне для экономии средств или других ресурсов.
Ключевые выводы
- Аутсорсинг процессов знаний (KPO) заключает контракты на работу, основанную на знаниях, с квалифицированными экспертами в предметной области.
- Компании обращаются к КПО, когда им нужны специальные знания и опыт, и когда им не хватает квалифицированных специалистов в штате.
- В идеале компании обращаются к КПО за одновременной возможностью получения высококвалифицированной рабочей силы по более низкой цене.
Нажмите «Воспроизвести», чтобы узнать, что такое аутсорсинг процессов знаний (KPO)
Понимание аутсорсинга процессов знаний
Аутсорсинг процессов знаний — это целенаправленное распределение задач относительно высокого уровня, связанных со специализированными знаниями или решением проблем , сторонней организации или третьей стороне, обладающей высоким уровнем знаний в предметной области, часто расположенной в другом географическом регионе, чем сама компания.
KPO отличается от аутсорсинга бизнес-процессов (BPO), который предполагает передачу рабочей силы и другой оперативной работы третьей стороне для экономии денег. Хотя KPO является частью BPO, KPO включает в себя гораздо более специализированную, аналитическую и основанную на знаниях работу.
Компании, участвующие в КПО, стремятся получить высокообразованных и квалифицированных специалистов без затрат на обучение и подготовку этих работников для выполнения разовых или специальных проектов, которые не являются частью повторяющейся деятельности. С помощью КПО компания может быстро нанимать специалистов в конкретных областях для повышения конкурентоспособности и увеличения доходов или для выполнения специальных задач, для которых нет необходимости нанимать специалистов в данной области на постоянной основе на постоянной основе.
Виды услуг КПО
Некоторые распространенные примеры доменов аутсорсинга КПО включают:
- Финансовые консультанты
- Исследования и разработки (НИОКР)
- Коммерческие операции (управленческий консалтинг)
- Технический анализ
- Инвестиции
- Юридический
- Медицина и здравоохранение
- Анализ и интерпретация данных
Причины для аутсорсинга процесса знаний
Компании обращаются к КПО, когда им нужны специализированные знания и опыт, когда эти знания или навыки не могут быть найдены внутри компании.![]() Однако компании, участвующие в КПО на шельфе, также обычно делают это, чтобы сократить расходы, нанимая квалифицированных рабочих с более низкой заработной платой в другом месте, вместо того, чтобы нанимать их напрямую в качестве сотрудника. В идеале компании обращаются к КПО за одновременным получением высококвалифицированной рабочей силы по более низкой цене.
Однако компании, участвующие в КПО на шельфе, также обычно делают это, чтобы сократить расходы, нанимая квалифицированных рабочих с более низкой заработной платой в другом месте, вместо того, чтобы нанимать их напрямую в качестве сотрудника. В идеале компании обращаются к КПО за одновременным получением высококвалифицированной рабочей силы по более низкой цене.
Например, производитель может использовать сырье, повышать ценность этих материалов с помощью различных процессов, а затем продавать результат как конечный продукт. Компания может обратиться к КПО, чтобы определить, как повысить эффективность своего производственного процесса, чтобы получить максимальную отдачу при минимально возможных общих затратах. Результат КПО также может помочь компании создать конкурентное преимущество.
Преимущества и недостатки КПО
КПО может помочь компаниям снизить операционные или производственные затраты за счет создания новых процессов или повышения эффективности. КПО также заполняет пробел или потребность в квалифицированных сотрудниках в определенной области. КПО также освобождает существующий персонал, включая руководство, для выполнения другой работы, повышая эффективность и производительность.
КПО также освобождает существующий персонал, включая руководство, для выполнения другой работы, повышая эффективность и производительность.
Гибкость, которую дает КПО, позволяет компании легко увеличивать или сокращать персонал. Например, в случае ухудшения экономических условий компания может легко сократить штат КПО, чтобы сократить расходы. И наоборот, компания может быстро нанять специализированный персонал для увеличения прибыли или доходов. КПО помогает компании быть более гибкой и адаптироваться к изменениям в своей отрасли и конкурентной среде.
Однако у КПО есть недостатки. Конфиденциальность интеллектуальной собственности и безопасность бизнеса могут быть поставлены под угрозу, если секретная или конфиденциальная информация будет утеряна, скопирована или передана конкуренту. Компании меньше контролируют процесс найма аутсорсинговых работников. В результате компания может быть не в состоянии обеспечить характер своих аутсорсинговых сотрудников или качество их работы.
Внедрение КПО может потребовать много времени и ресурсов для обеспечения успешной работы. Кроме того, общение может быть проблемой и проблемой из-за правовых, языковых и культурных барьеров. Другим недостатком может быть то, что существующие сотрудники могут чувствовать угрозу от найма аутсорсинговых работников и чувствовать, что их рабочие места находятся под угрозой.
Что такое КПО (аутсорсинг процессов знаний)?
Аутсорсинг процессов знаний относится к форме аутсорсинга основной, связанной с информацией рабочей деятельности, выполняемой сотрудниками разных компаний или дочерней компанией одной и той же компании с целью экономии средств и ресурсов.
Аутсорсинг процессов знаний (KPO)
Аутсорсинг процессов знаний относится к форме аутсорсинга основной, связанной с информацией рабочей деятельности, выполняемой сотрудниками разных компаний или дочерним предприятием той же компании с целью экономии затрат и ресурсов .
КПО включает в себя высокоценную работу, такую как исследования, разработки, анализ и консультации, которые выполняются квалифицированным персоналом. Иногда фирмы КПО предлагают услуги по принятию низкоуровневых, легко запоминаемых бизнес-решений от имени компании-источника.
Причины для аутсорсинга процессов знаний
Компании обычно обращаются к КПО в таких ситуациях, как:
— когда им нужны специальные знания и опыт
— когда им не хватает квалифицированных специалистов
— когда у них есть возможность сократить расходы за счет найма квалифицированных рабочих с более низкой заработной платой в другом месте
В основном компании делают это, когда чувствуют, что могут улучшить свою цепочку создания стоимости.
Плюсы и минусы аутсорсинга процессов знаний
— снижает затраты компании на деятельность или продукцию
— компенсирует нехватку квалифицированных кадров в определенной области
— высвобождает человеческий капитал для выполнения другой работы
— безопасность может быть нарушена, а конфиденциальная информация может быть потеряна
— трудно удерживать таланты на сторонних должностях
— требуется время и ресурсы для успешного создания КПО
— возникают трудности в общении из-за языковых/культурных различий
Используете ли вы современное программное обеспечение для подбора персонала? Если нет, вы упускаете возможность.
